
The Lost Science: How We Forgot Security Was a Graph Problem
In 1976, computer scientists proved that security is a graph traversal problem. Then we forgot. Here's why, and why it matters now.
If you ask a modern security architect how access control works, they'll describe Access Control Lists: users, groups, permissions, roles. Flat tables. Lookup operations.
But if you asked the same question to a computer scientist in 1976, they would have drawn you a graph. Nodes for subjects and objects. Directed edges for rights. And they would have told you: "Security is the question of whether a path exists."
We knew this. We proved it. Then we forgot it. It was not wrong, but we couldn't afford to compute it.
This is the story of how security became a graph problem, why we abandoned that insight, and why graph databases now let us pick it back up.
The golden age: when security was mathematics (1973-1983)
The early 1970s were an unusual period for computer security. The field wasn't dominated by vendors selling products. It was dominated by mathematicians asking fundamental questions:
"Can we prove that a system is secure?"
The answers they developed weren't heuristics or best practices. They were formal models: mathematical frameworks that could provide actual guarantees. And almost all of them were graph problems.
Bell-LaPadula: confidentiality as information flow (1973)
David Elliott Bell and Leonard LaPadula, working for MITRE under a US Air Force contract, asked: "How do we prevent classified information from leaking to unauthorized users?"
They modeled security clearances as a lattice—a mathematical structure where elements have a defined ordering (Top Secret > Secret > Confidential > Unclassified). Then they defined two simple rules:
- No Read Up (Simple Security): A subject cannot read an object at a higher classification level.
- No Write Down (Star Property): A subject cannot write to an object at a lower classification level.
Information flow is directional. If you model clearances as nodes and permitted flows as edges, then a security violation is simply a path that shouldn't exist. Confidentiality becomes a graph reachability problem.
Biba: the integrity inverse (1977)
Kenneth Biba, working at MITRE on a different problem, realized that integrity is the mirror image of confidentiality.
Where Bell-LaPadula asks "Can secrets leak down?", Biba asks "Can corruption flow up?"
His model inverted the rules:
- No Read Down: A subject cannot read from a lower integrity level (don't trust untrusted data).
- No Write Up: A subject cannot write to a higher integrity level (don't corrupt trusted data).
Same lattice structure. Same graph problem. Different direction of concern.
Together, Bell-LaPadula and Biba showed that both confidentiality and integrity could be modeled as constrained information flow on a graph. Security was about proving that certain paths could never exist. Not checking permissions.
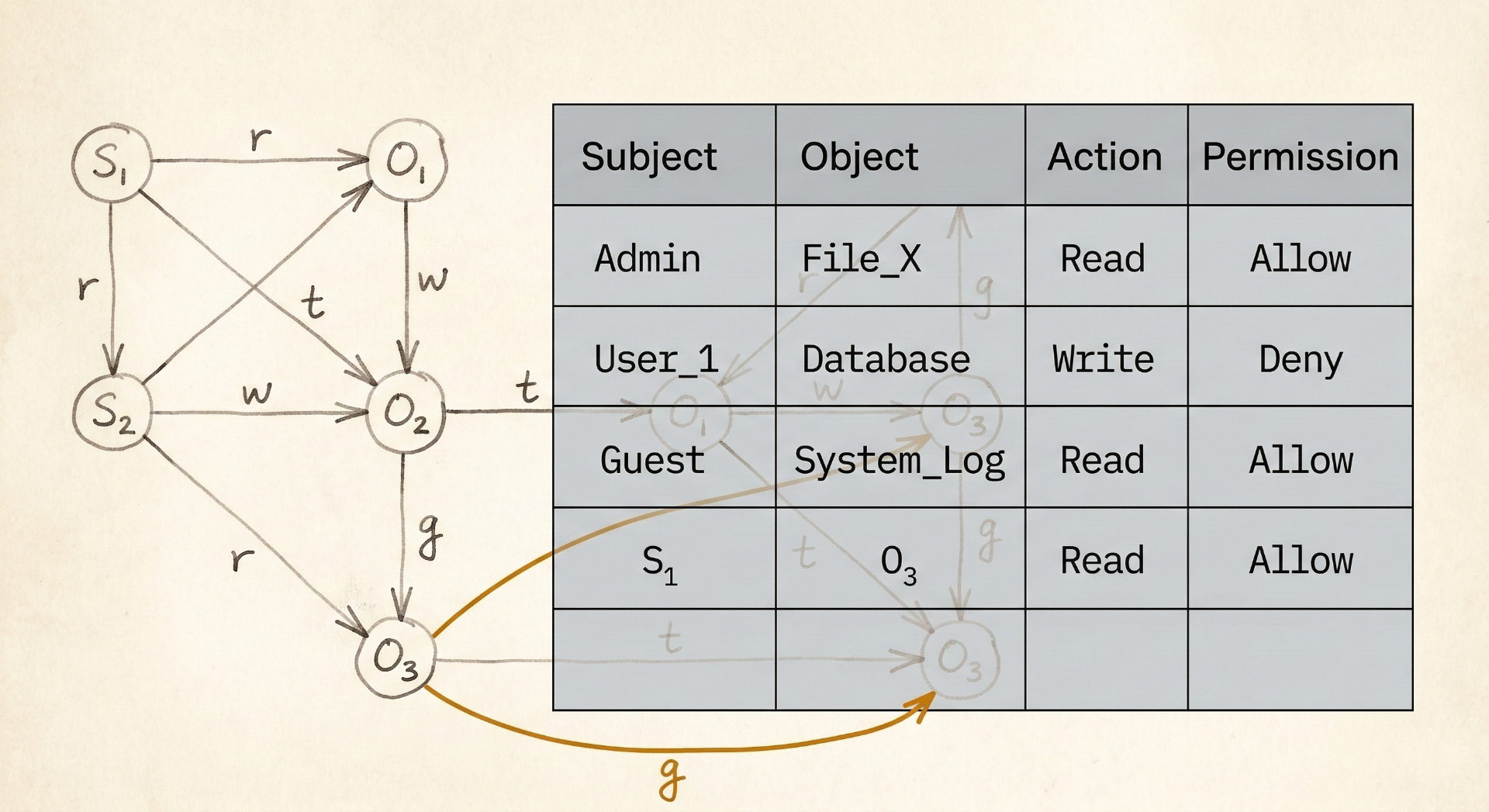
Take-Grant: security as graph rewriting (1976)
While Bell-LaPadula and Biba focused on information flow, Jones, Lipton, and Snyder asked a different question: "How do permissions propagate?"
Their Take-Grant model was explicitly a directed graph:
- Nodes: Subjects (users, processes) and Objects (files, resources)
- Edges: Rights (read, write, take, grant)
The model defined four operations that could modify the graph:
- Take: If A has "take" rights to B, and B has rights to C, then A can acquire B's rights to C.
- Grant: If A has "grant" rights to B, A can give B any rights that A possesses.
- Create: A subject can create new nodes.
- Remove: A subject can remove edges it controls.
The security question became: "Given an initial graph and these rewriting rules, can subject X ever acquire right R to object Y?"
This is pure graph theory, and the result: the safety problem in Take-Grant is decidable in linear time. You can actually prove whether a right can ever leak.
Harrison-Ruzzo-Ullman: the limits of decidability (1976)
Not all news was good. Harrison, Ruzzo, and Ullman studied a more general access control model and proved the result: in the general case, the safety problem is undecidable.
You cannot write an algorithm that will always correctly determine whether a given access control system can ever reach an unsafe state.
But they also showed that restricted models are decidable. If you constrain the graph structure (limit the operations, bound the complexity), you can recover formal guarantees.
The theorists had mapped the terrain: security is a graph problem, and the key question is whether your graph is constrained enough to be analyzable.
The pragmatic retreat: why we over-corrected (1980s-2000s)
If security was solved in theory by 1983, why are we still struggling with access control in 2026?
Two forces pushed at once, and we over-corrected for both.
The hardware reality
In 1976, a PDP-11 had 64KB of RAM. Graph traversal algorithms that are trivial today were prohibitively expensive. Running a Take-Grant safety analysis on a real system with thousands of users and objects? Impossible.
The formal models were correct but practically useless.
The models' own limitations
Computational cost wasn't the only problem. The formal models themselves had rough edges that made practitioners skeptical.
Bell-LaPadula's "tranquility" property required that security labels never change during operation. That was too rigid for real systems where users legitimately need to reclassify data. Biba's integrity lattice couldn't capture what commercial systems actually needed: separation of duties, well-formed transactions, audit trails.
Clark and Wilson recognized this in 1987. Their integrity model abandoned the lattice approach entirely. Real-world integrity, they argued, isn't about information flow direction. It's about ensuring that data is only modified through authorized, validated procedures. They were right about that.
But the lesson the industry drew was broader than Clark and Wilson intended. The takeaway wasn't "lattice models need refinement." It was "formal models don't work in practice." That was the over-correction. The models needed better hardware and more nuance. Instead, we threw out the graph entirely.
The compromise: flatten the graph
System designers needed something that would actually run. Their solution was to flatten the graph into tables:
- Access Control Lists (ACLs): For each object, list who can access it.
- Capability Lists: For each subject, list what they can access.
Both are projections of the underlying graph onto flat structures. They're fast to query (O(1) lookup), easy to store, and simple to understand.
But they can't answer path questions.
An ACL can tell you "Alice has read access to File X." It cannot tell you "If Alice compromises Service A, can she eventually reach Database Z?" That's a multi-hop traversal, exactly what ACLs were designed not to compute.
What we lost
When we flattened the graph, we lost the ability to answer the questions that actually matter:
| Question | Graph Model | ACL Model |
|---|---|---|
| "Can Alice access File X?" | Trivial | Trivial |
| "Can Alice ever reach Database Z?" | Path query | Manual analysis |
| "If we add this permission, what new paths open?" | Graph diff | Unknown |
| "Where are the transitive trust relationships?" | Traversal | Invisible |
| "Is our permission structure safe?" | Decidable (constrained) | Undecidable (in practice, unknown) |
We traded formal guarantees for performance and simplicity. For 30 years, that was a reasonable trade.
But the constraints that forced it have been gone for over a decade. At some point, a reasonable compromise becomes an unexamined habit.
The irony: we rebuilt the graph (badly)
The irony is that modern enterprise security has recreated the graph problem at massive scale while still pretending we have flat ACLs.
Cloud IAM: the implicit graph
Look at AWS IAM:
- IAM Users and Roles are subjects
- Resources (S3 buckets, EC2 instances, Lambda functions) are objects
- Policies define edges
- AssumeRole is literally the "take" operation from Take-Grant
- Resource-based policies create cross-account edges
AWS IAM is a graph. But AWS gives you no native tools to query it as one. You get the IAM Policy Simulator: a point query tool in a world that needs path analysis.
So security teams discover that a misconfigured role in Account A can assume into Account B, which has a policy that allows access to Account C's production database. Three hops. Invisible to any single ACL review.
The Kubernetes permission graph
Kubernetes might be the worst offender. ServiceAccounts, Roles, RoleBindings, ClusterRoles, ClusterRoleBindings. All edges in a graph. Namespace boundaries create subgraphs. Pod security contexts add more nodes.
And the graph has hidden edges that RBAC doesn't model. A ServiceAccount with permission to list Secrets in a namespace can read every token stored there, including tokens for more privileged ServiceAccounts. That's a path through two different edge types (RBAC grants access to Secrets, Secrets contain credentials) that no single kubectl auth can-i check will ever surface. It's Biba's integrity problem in miniature: low-trust workloads reading their way up to high-trust credentials.
Active Directory: the original sin
Active Directory has been a graph since 1999. Users, Groups, OUs, GPOs, Trust Relationships. All edges in a directed graph. Nested group memberships create transitive paths. Trust relationships create cross-domain paths.
Every AD privilege escalation attack (Kerberoasting, DCSync, Golden Ticket paths) is a graph traversal exploit. The attackers know this. In 2016, the BloodHound project made it explicit: ingest AD relationships, build a directed graph, find the shortest path to Domain Admin. It works devastatingly well precisely because it models AD as what it actually is.
Defenders, meanwhile, run Get-ADUser queries and review group memberships in spreadsheets.
We've spent 25 years defending against graph attacks with table tools.
BloodHound has been open-source since 2016. Defenders can use it too. But BloodHound answers an attacker's question: "What's the shortest path to Domain Admin?" The defensive inverse — "show me everything that can reach our crown jewels, continuously, across every environment" — needs different tooling and a different architectural commitment. One most security teams haven't made, because nobody is selling it to them.
The return: graph databases make this practical
In 2007, Neo4j released the first production graph database. By 2015, graph databases were mainstream. The computational barrier that forced us to abandon formal models in the 1980s no longer exists.
Graph traversal that was impossible on a PDP-11 now runs in milliseconds on commodity hardware. A path query that answers "Can Principal X ever reach Resource Y through any chain of permissions?" is a single Cypher statement. Tools like AWS Access Analyzer have started nibbling at this problem, but they're still point queries against specific policy combinations, not full path traversals across trust boundaries.
The difference matters. A point query tells you whether one specific permission is granted. A graph query tells you whether a path exists that you never intended to create. The three-hop AWS role chain, the Kubernetes Secret that bridges two privilege levels, the nested AD group that grants Domain Admin through six degrees of membership. These are all paths. They're invisible to point queries and obvious to graph traversal.
The 1970s papers showed that if you model your system as a graph with appropriate constraints, you can prove security properties. For 40 years, nobody had the hardware to act on that. Now we do. A graph database holding your IAM policies, network topology, trust relationships, and data flows can answer questions that no combination of ACLs, spreadsheets, and manual reviews can touch.
The safety guarantees that Bell, LaPadula, Biba, and the Take-Grant authors described are implementable now, provided you constrain the model appropriately. The HRU undecidability result still holds for the general case. But most real systems are constrained, and that's exactly where the formal results apply.
Some vendors are catching on. Wiz builds attack graphs across cloud environments. XM Cyber models attacker paths to critical assets. These are real steps forward — they ask path questions, not point questions. But they solve half the original problem: they find paths that exist right now. The formal question the 1970s models posed was stronger: can this system ever reach an unsafe state? That's the difference between a snapshot and a proof. Graph databases give us the machinery for both. The industry has mostly picked up the first half. The mainstream vendor ecosystem is still selling better ACL management.
The question we should be asking
The security industry has spent two decades building increasingly sophisticated ACL management tools. Better UIs for permission tables. More granular RBAC. More complex policy languages. All of it optimizing the lookup.
None of it asks whether the path exists.
The 1970s theorists were decades ahead of the hardware. They understood that security is about paths, flows, and reachability. They built formal models to prove it, and then had to shelve those models because nothing could run them fast enough.
The hardware caught up 15 years ago. The question is why we're still pretending that flattening a graph into ACLs is anything other than a legacy compromise.
What's left
That said, recognizing the problem and fixing it are different things. Graph databases are mature. A few vendors are asking path questions. The attack side has been thinking in graphs for a decade. But this still isn't how most defenders work.
The theory has been there since the 1970s. The compute is there now. The attackers figured it out a decade ago. We're still waiting for the defenders to close the loop.
References & further reading
The original papers, if you're curious:
- Bell, D.E. & LaPadula, L.J. (1973). "Secure Computer Systems: Mathematical Foundations" - MITRE Technical Report
- Biba, K.J. (1977). "Integrity Considerations for Secure Computer Systems" - MITRE Technical Report
- Harrison, M.A., Ruzzo, W.L., & Ullman, J.D. (1976). "Protection in Operating Systems" - Communications of the ACM
- Clark, D.D. & Wilson, D.R. (1987). "A Comparison of Commercial and Military Computer Security Policies" - IEEE Symposium on Security and Privacy
- Lipton, R.J. & Snyder, L. (1977). "A Linear Time Algorithm for Deciding Subject Security" - Journal of the ACM
These papers are freely available and shorter than you'd expect. The notation looks dated, but the proofs hold.