
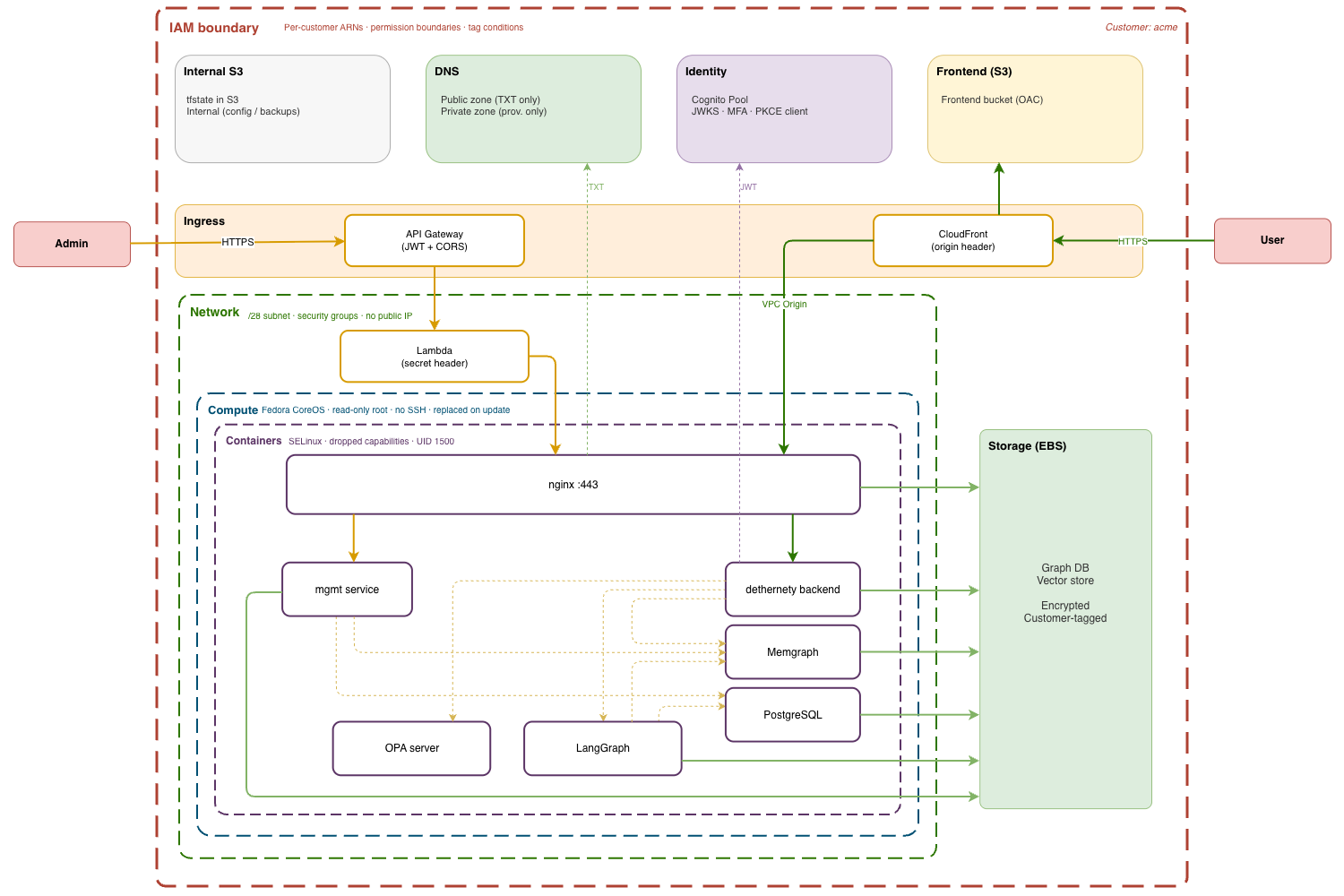
Customer isolation from the infrastructure up
The previous article described an architecture where each customer gets their own subnet, Cognito pool, S3 buckets, Terraform state, and deployer. This article explains the constraint behind those decisions and traces it through the infrastructure, layer by layer. Later articles go deeper into the implementation of each component.
The constraint is blast radius. Every boundary in the architecture exists to answer one question: if this component is compromised, what can it reach?
The organizing principle
Application-level isolation — tenant ID checks, middleware, row-level security — fails when any check is wrong: a missing filter, a misconfigured middleware, a bypassed code path. Infrastructure-level isolation fails differently. A provisioner role that contains arn:aws:s3:::{prefix}-acme-{suffix}-internal and not arn:aws:s3:::{prefix}-corp-{suffix}-internal cannot access Corp's bucket regardless of what the application does. The reference doesn't exist in the policy document. AWS denies the request before it reaches any application code.
The principle is to push isolation down the stack — into IAM policies, subnet boundaries, DNS zones, Cognito pools, S3 bucket policies, Terraform state paths — so that each layer enforces containment on its own. The blast radius of a compromise is the intersection of all layers, not the weakest one. A compromise must bypass all of them to reach another customer.

IAM: hardcoded ARNs, no wildcards
IAM determines what stolen credentials can reach. In a shared-everything architecture, a compromised role with s3:GetObject on arn:aws:s3:::platform-* can read every customer's bucket. The wildcard is the blast radius.
This architecture eliminates wildcards from per-customer policies. The provisioner role for customer Acme contains arn:aws:s3:::{prefix}-acme-{suffix}-internal. The role for Corp contains arn:aws:s3:::{prefix}-corp-{suffix}-internal. Terraform templates the customer ID into every ARN at creation time.
The same applies to every other AWS service in the stack. Route53 zone IDs, subnet ARNs, Cognito pool ARNs, Lambda function ARNs, CloudWatch log group paths. All customer-specific, all hardcoded.
The roles form a chain that narrows scope at each step:
Bootstrap creates S3 state buckets and the platform IAM user. Runs once, by the operator.
Platform creates shared infrastructure: VPCs, container registries, the parent DNS zone, shared IAM roles. Broad permissions within the platform account, but no per-customer resources.
Provisioner is per-customer. Inline policies containing hardcoded ARNs for this customer's resources only. A permission boundary caps the maximum scope. Even if an inline policy is misconfigured, the boundary prevents escalation beyond this customer's resource set.
Runtime is the EC2 instance profile. Narrower still: S3 read/write for the customer's own buckets, ECR pull for shared container images, CloudWatch scoped to one log group, and Route53 restricted to TXT records in one public zone (for certificate renewal). No permissions to create or destroy infrastructure.
Each customer's Fargate deployer has a role with exactly one permission: sts:AssumeRole on that customer's provisioner role. The trust policy requires the customer ID as an external ID, preventing confused deputy scenarios:
# The deployer task role — one permission, one customer
{
"Effect": "Allow",
"Action": "sts:AssumeRole",
"Resource": "arn:aws:iam::${account_id}:role/${prefix}-${customer_id}-infra-provisioner"
}
The chain — deployer task credential → provisioner role → customer resources — narrows at each step. No step can widen it. A compromised deployer can assume the provisioner role for its customer and nothing else. A compromised provisioner can touch its customer's resources and nothing else.
Where resource ARNs aren't known at creation time (EC2 instances, for example), tag-based conditions provide equivalent scoping. The provisioner applies a Customer tag at creation time through an aws:RequestTag condition, and subsequent operations are restricted to resources carrying that tag via aws:ResourceTag. The tag is set once, at creation, and the condition is evaluated by AWS, not by application code.
Network: one subnet, no cross-tenant paths
The workload runs in two VPCs within a single cell. The broader account structure (security, logging, account-level monitoring) is outside this article's scope. The management VPC hosts deployers and workload monitoring. The customer VPC hosts customer environments. VPC peering connects them, but routing rules prevent customer instances from initiating connections to the management plane.
Each customer gets a /28 subnet in the customer VPC (sixteen addresses, eleven usable after AWS reservations). No instance has a public IP. Inbound traffic arrives through two paths only: a CloudFront VPC Origin and a per-customer Lambda, both routed over internal AWS networks, not the public internet.
The security group on a customer's instance allows HTTPS ingress from exactly two sources: the CloudFront VPC Origin security group and a per-customer Lambda security group (for the management API). No security group rule allows traffic between customer subnets.
A compromised instance in Acme's /28 has no network path to Corp's /28. No security group rule provides it. No route table entry enables it. The instance can reach the internet through a shared NAT instance for outbound calls, but it cannot initiate connections to other customer subnets, to the management VPC, or to any other internal resource. There is nothing to discover at the network layer.
DNS: two zones, two permission sets
Each customer has two Route53 hosted zones for the same domain, for example acme.dethernety.io.
The public zone is internet-resolvable. It holds the CloudFront ALIAS record that routes user traffic, the ACM validation CNAME for the CloudFront TLS certificate, and Let's Encrypt DNS-01 challenge TXT records for the backend TLS certificate. The EC2 instance can write to this zone for certificate renewal, but its IAM policy restricts modifications to TXT records only:
{
Effect = "Allow"
Action = ["route53:ChangeResourceRecordSets"]
Resource = "arn:aws:route53:::hostedzone/${var.public_zone_id}"
Condition = {
"ForAllValues:StringEquals" = {
"route53:ChangeResourceRecordSetsRecordTypes" = ["TXT"]
}
}
}
The instance cannot modify A records, CNAME records, or any routing record. A compromised instance with Route53 credentials cannot redirect traffic to a different origin.
The private zone is VPC-associated only — not resolvable from the internet. It holds the instance's private IP for internal service discovery. CloudFront's VPC Origin resolves the backend through this zone. Only the provisioner role can write to it; the instance profile has no permissions for the private zone at all.
DNS is a privilege escalation vector. Control over DNS records means the ability to redirect traffic, intercept requests, and steal tokens. Split-horizon DNS with scoped IAM policies limits what a compromised instance can do: renew its own TLS certificate (TXT records in the public zone), but not redirect traffic (A/CNAME records) and not modify internal routing (private zone).
Identity: one Cognito pool per customer
Each customer gets a separate Cognito User Pool — not a shared pool with tenant-ID attributes, but a distinct AWS resource with its own ARN, password policy, MFA configuration, and PKCE app client.
A shared pool is simpler to manage and works for most platforms. But it creates a shared authentication surface. A misconfigured Lambda trigger, a broken attribute mapping, or a token-handling bug in a shared pool affects every customer's authentication at once. The blast radius of an identity misconfiguration is every tenant.
With per-customer pools, the blast radius is one customer. The app client's callback URLs point to this customer's subdomain. Self-registration is disabled. The JWT tokens issued by one pool are validated against that pool's JWKS endpoint. A token from Acme's pool is meaningless to Corp's backend: the issuer doesn't match, the audience doesn't match, the signing keys are different.
Storage: no shared data layer
Each customer has two S3 buckets and a dedicated EBS volume. No shared database engine. No shared storage backend.
Bucket names include a random suffix generated at provisioning time: {prefix}-acme-{random}-internal rather than the predictable {prefix}-acme-internal. S3 bucket names are globally unique, and predictable names are a known attack vector: an adversary who can guess the name can pre-create the bucket in another account and intercept data written to it before the legitimate owner provisions. The suffix makes the name unguessable.
The frontend bucket serves static assets through CloudFront Origin Access Control. The bucket policy allows access only from one CloudFront distribution, identified by ARN. No other distribution, and no direct access.
The internal bucket holds Ignition configuration, Terraform outputs, backups, and state files. Public access is blocked at every level: block_public_acls, block_public_policy, ignore_public_acls, restrict_public_buckets, all enabled. Versioning is on for recovery. Lifecycle rules manage retention: backups archive to Glacier after seven days, state versions expire after ninety days.
The EBS volume stores the graph database, vector store, and supporting services. Encrypted at rest, tagged with the customer ID, persistent across instance replacements. The instance profile's IAM policy restricts volume operations to volumes carrying this customer's tag. A compromised instance can access its own data volume but cannot discover or attach another customer's.
The cost is higher than a multi-tenant RDS cluster or a shared S3 prefix. The tradeoff is that every storage boundary (bucket names, bucket policies, IAM ARNs, volume tags) is enforced by AWS, not by application logic in the request path.
State: one Terraform state file per customer
Terraform state files contain infrastructure metadata: resource IDs, ARNs, configuration values, and sometimes sensitive outputs. In a shared-state architecture, a corrupted state file or an accidental terraform destroy affects every customer provisioned from that state.
This architecture isolates state at every level. Bootstrap uses local state; the S3 bucket doesn't exist yet. Platform state lives in a dedicated S3 object. Each customer's account state lives in a shared bucket under a customer-specific key path. Each customer's infrastructure state lives in that customer's own internal S3 bucket.
The provisioner role for Acme can read and write Acme's state. It cannot read Corp's. The ARN isn't in the policy. Concurrent provisioning operations run against separate state files with separate DynamoDB locks. An accidental terraform destroy against Acme's state tears down Acme's infrastructure and nothing else.
Compute: immutable, replaceable, contained
The EC2 instances run Fedora CoreOS: a read-only root filesystem, no package manager, no SSH by default. The entire OS configuration is defined in a Butane YAML file, compiled to Ignition JSON, uploaded to S3, and fetched at first boot. The instance is not configured after launch. It boots into its final state.
Updates replace the entire instance. Terraform detects a change in the Ignition configuration, terminates the old instance, launches a new one, and reattaches the persistent EBS data volume. No in-place patching, no configuration drift, and no persistence across replacements. An attacker who compromises an instance loses that access when the next deployment replaces it. The root volume is destroyed. The new instance boots from a clean configuration.
Inside the instance, containers run on a Podman bridge network under systemd. The isolation model follows the same principle: minimize what each component can reach.
- Capabilities are dropped wholesale (
DropCapability=ALL), then the minimum set is re-added per container. nginx getsNET_BIND_SERVICEto bind port 443. Application containers get nothing beyond the default. - NoNewPrivileges is set on every container. Escalation through setuid binaries is blocked.
- Root filesystems are read-only, with tmpfs for runtime data (cache, PID files).
- SELinux runs in enforcing mode. Volume mounts use
:Zlabels for mandatory access control. Each container's files are labeled for that container's context only. - Resource limits are set per container (memory hard and soft limits). A runaway process can't starve other services.
- Application processes run as unprivileged users (a dedicated UID), not root.
A container escape still faces the read-only host filesystem, SELinux context boundaries, and an instance profile scoped to one customer's resources. The layers above (IAM, network, DNS, storage) don't care what happened inside the container.
Ingress: two paths, separate secrets
Many platforms implement management as routes within the application: same process, same authentication middleware, same database connection. A bug in the app exposes the management surface. A bug in management exposes user data. Here, the management function is not part of the application. It runs on separate infrastructure: a separate entry point, separate compute, separate authentication, separate credentials.
Traffic reaches a customer's environment through two paths. The data path serves user requests through CloudFront. The admin path handles management operations through API Gateway and Lambda. The two share no secrets.

The data path runs through a dedicated CloudFront distribution that accepts one hostname (acme.dethernety.io), serves static assets through Origin Access Control (restricted to this distribution's ARN), and forwards API requests through a VPC Origin to an ENI in the customer's /28 subnet. CloudFront injects a customer-specific secret header into every forwarded request. nginx validates this header before processing anything. A request that didn't arrive through the correct distribution is rejected.
The admin path runs through a per-customer API Gateway and an ephemeral Lambda function in the customer's subnet. API Gateway validates the JWT against this customer's Cognito pool before the request reaches any code. CORS is restricted to the customer's domain. The Lambda runs with a security group that allows egress only to the backend. It starts clean from a container image, processes the request, injects its own secret header (distinct from the CloudFront header), and forwards to nginx. The management service on the instance re-validates the JWT against Cognito's JWKS endpoint from scratch, trusting nothing upstream.
The two paths share no infrastructure and no credentials. An attacker who obtains the CloudFront origin header can forge data-path requests to one customer's backend but knows nothing about the Lambda secret. An attacker who obtains the Lambda secret can reach the management service but knows nothing about the CloudFront header.
Where the boundaries intersect
What matters for blast radius is what an attacker actually reaches when a component falls. Take the worst case within a customer boundary: a compromised EC2 instance.
The attacker gets the instance profile credentials, scoped to one customer's buckets, one log group, TXT records in one DNS zone. They get one /28 subnet with no routes to other subnets or the management VPC. They get a read-only filesystem with SELinux enforcing.
The containment holds because each boundary is enforced by a different AWS mechanism. IAM won't resolve cross-customer ARNs. Security groups have no cross-subnet rules. The Cognito pool is a separate AWS resource with different signing keys. The root volume is read-only (Fedora CoreOS), so there is nowhere to write a persistent backdoor, and the next deployment destroys the instance entirely and boots from a clean Ignition configuration. An IAM exploit doesn't open network routes. A container escape doesn't produce valid Cognito tokens.
Trade-offs
Per-customer isolation creates more resources. Each customer adds approximately six IAM resources, two Route53 zones, two S3 buckets, a Cognito pool, a /28 subnet, a CloudFront distribution, an API Gateway with a Lambda function, a Fargate deployer, and a dedicated EC2 instance. The Terraform modules are more complex because they template customer IDs, zone IDs, and subnet ARNs into every resource.
AWS service limits bound the number of customers per account. The architecture scales through cells: each cell is a separate AWS account with its own VPC pair, its own service limits, and its own blast radius boundary. At tens to low hundreds of customers per cell, the limits are not a constraint. Each cell is itself an isolation boundary, a second containment layer on top of the per-customer isolation within it.
Each individual resource is simpler to audit than its shared equivalent. Acme's provisioner policy contains Acme's ARNs. No wildcards to reason about. The complexity is in the quantity of resources, not in understanding what any single policy allows. An auditor reviewing Acme's provisioner role sees exactly what it can touch. There is no need to trace application logic to determine whether a shared role might reach another customer's data under certain conditions.
The operational cost is real: more state files, more deployers, more policies to manage. The architecture manages this through Terraform modules and automated provisioning pipelines. A new customer is a new set of module invocations with a different customer ID. Same modules, different parameters.
Series
- Architecture overview
- Customer isolation from the infrastructure up (this article)
- Automating isolation: the self-service deployment pipeline
- CloudFront VPC Origins: what breaks and how to fix it
This architecture is implemented in dether.net, a graph-native threat modeling platform. If you're interested in seeing these patterns applied to security architecture analysis, that's where they run in production.